Utilité et aversion au risque
Sur cette page nous débroussaillons l’un des concepts de la théorie du portefeuille : les fonctions d'utilité, appliquées à la finance.
Fonctions d’utilité
Le fait que des individus puissent implicitement se référer à des fonctions d'utilité sous-tend l'hypothèse de leur rationalité. Satisfaction est cependant un terme plus adéquat qu'utilité. On mesure donc un niveau de satisfaction. Par rapport à quoi ?
Pour un consommateur, il existe autant de fonctions d’utilité que de produits. Le schéma classique est que plus il possède un produit donné en quantité, plus il est satisfait (précisons bien qu'il s'agit d'un schéma classique, sans point de satiété ; il n'y a pas lieu d'être plus satisfait de recevoir une tonne d'exemplaires du journal du jour plutôt que d'en recevoir un seul, beaucoup moins encombrant !).

Cette rationalité s'observe dans d'autres problématiques. Un individu peut déterminer pour chaque niveau de richesse un degré « d’utilité ». La fonction ne représente alors pas la satisfaction apportée par un produit en particulier mais celle de sa richesse GLOBALE. Pour un investisseur, cette utilité peut être transposée à tout revenu financier futur (une courbe représentant tous les états de fortune a donc la même configuration qu'une courbe de flux espérés).
Comme on fait l’hypothèse que cette satisfaction peut être mesurée, on parle d’utilité CARDINALE (par opposition à l’utilité ordinale qui offre un cadre théorique aux courbes d’indifférence). Mais il n'existe pas d'unité de mesure normalisée de la satisfaction (ça se saurait) et les valeurs prises par cet indice seront purement arbitraires.
Appelons \(u\) la fonction d’utilité qui affecte à chaque niveau de revenu \(w\) un indice d'utilité. On suppose que \(u\) est continue et strictement croissante. De même que tout individu même très riche préfère être encore plus riche plutôt que se satisfaire de son enviable condition, l'investisseur préfère recevoir des revenus financiers toujours plus élevés. Donc, la dérivée \(u’(w)\) est strictement positive.
En revanche, plus l’individu est riche et moins sa satisfaction augmente pour un accroissement de richesse donné. L’utilité marginale est décroissante. Si l’on étudie la dérivée seconde, on a \(u’’(w) < 0\) (fonction concave). On peut toutefois envisager une satisfaction indépendante du niveau de richesse (fonction affine) avec dérivée seconde nulle, voire des individus qui souhaitent recevoir de plus en plus d’argent au fur-et-à-mesure qu’ils s’enrichissent (fonction convexe).
La fonction d'utilité d'un investisseur qui souhaite obtenir un revenu financier en plaçant une certaine somme d'argent se construit à l'aide des probabilités. Voir à cet égard la page construction d'une fonction d'utilité probabilisée.
Supposons deux niveaux de revenu espérés \(W_1\) et \(W_2,\) donc deux situations de choix. La courbe représentative de la fonction d’utilité est tracée ci-dessous en rouge. L’espérance entre les valeurs de \(W_1\) et \(W_2\) se trouve nécessairement en-dessous, sur une droite (en vert). En effet, une espérance est une combinaison linéaire de valeurs de \(W.\)
Le graphique ci-dessous montre qu'à indice d'utilité égal, l’espérance de revenu ainsi déterminée s’écarte du niveau de revenu que l'investisseur espère. Celui-ci, noté \(Wc,\) est appelé équivalent certain (voir l'exemple de la page développements limités). L’écart entre ces deux revenus, en orange sur le graphique, est la prime de risque. En pratique, l’évaluation de cette prime est un élément du choix entre un actif non risqué (bon du Trésor) et un risqué (action, notamment). Un exemple de calcul figure en page espérance d'utilité.
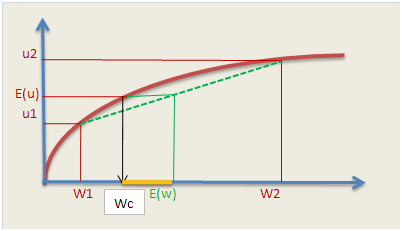
Pour mémoire, un investisseur peut aussi être neutre vis-à-vis du risque (la fonction d’utilité est affine), voire « risquophile » s'il est très joueur (fonction représentée par une courbe convexe). Mais souvent, il est risquophobe puis, au-delà d’un certain niveau de richesse, il devient de plus en plus insensible au risque et la courbe représentative de la fonction d’utilité admet une asymptote oblique.
Exemple
Soit une fonction d’utilité qui n’est autre que la fonction logarithme népérien (du moins sur sa partie positive).
Le niveau de richesse d’un investisseur s'établit à 10 000. Son choix d’investissement se traduit par les probabilités suivantes : 0,2 d’enregistrer une baisse de 2 000, 0,2 de rester au même niveau et 0,6 de gagner 4 000. Formellement, on résume ainsi la situation (\(L\) signifie Loterie et le tilde rappelle la qualité de variable aléatoire) :
\(\widetilde w\) \(=\) \(L(-2000, 0, 4000\;;0,2,\;0,2,\;0,6)\)
Cherchons d’abord l’équivalent certain.
Nous avons \(\ln(Wc)\) \(=\) \(0,2\ln 8000 + 0,2\ln10000 + 0,6\ln 14000,\) soit 9,3676.
\(Wc = e^{9,3676} = 11\,703.\) Le prix de la loterie s’établit à 1 703. Passons sur l’enfantin calcul de l’espérance de gain. Solution : 2 000.
Comme nous l’avons vu, la prime de risque est la différence entre équivalent certain et espérance de gain. Pour notre investisseur, elle s’élève donc ici à 297. C’est le montant maximal que l’investisseur pourrait dépenser pour éviter la loterie. Pour un risquophile, la prime serait négative.
L’aversion absolue pour le risque
Cette prime de risque apparaît aussi comme le produit de deux éléments, un coefficient propre à la loterie et une valeur subjective propre à l’investisseur appelée aversion absolue au risque.
Mathématiquement, on ne détermine pas cette décomposition de façon exacte mais grâce à un développement limité de Mc Laurin. Selon le type de fonction, l’approximation (due à J. Pratt) peut même être assez mauvaise puisqu’on se cantonne au degré 2 du développement.
La composante objective est la moitié de la variance de la loterie. Calculons la variance.
\({\sigma ^2}\widetilde w\) \(=\) \(E(\widetilde w^2) - [E(\widetilde w)]^2\) \(=\) \(0,2(-2000)^2 + 0,6(4000)^2 - 2000^2\) \(=\) \(6\,400\,000\)
La moitié de cette somme vaut 3 200 000.
Le coefficient d’aversion absolue au risque n’est pas difficile à mémoriser : \(A = - \frac{u''(w)}{u'(w)}\)
Dans notre exemple, il est égal à \(-\frac{u''(10000)}{u'(10000)}.\) Rappelons que la dérivée de \(\ln (w)\) est \(\frac{1}{w}\) et que la dérivée seconde est \(-\frac{1}{w^2}.\) Le coefficient d’aversion absolue au risque s’établit donc à \(\frac{1}{10\,000}.\)
Le produit des deux composantes donne 320. On remarque une différence d’environ \(10\,\%\) avec le calcul exact.
L’aversion relative pour le risque
Ici, la prime de risque varie avec le niveau de richesse. Ainsi, \(R = -w \frac{u''(w)}{u'(w)}\)
La fonction logarithme permet de modéliser une aversion relative CONSTANTE (puisque \(R = w_A = 1).\)
Lien
Accédez gratuitement aux primes de risque des sociétés du SBF 120 ou en accès payant pour un périmètre plus large...
https://www.fairness-finance.com
