Valeurs absentes d'une base de données
Elles sont au data analyst ce que sont les limaces au jardinier, les blessures au sportif ou le mauvais temps au marchand de glaces : une sorte de fatalité avec laquelle il faut composer. En effet, les données comportent invariablement des valeurs manquantes et des valeurs aberrantes…
La gestion des valeurs manquantes
Certaines techniques statistiques ne supportent pas qu’une donnée soit incomplètement renseignée. L’analyste choisit alors soit de l’exclure, soit d’affecter une valeur aux champs du fichier qui en sont dépourvus. Ce choix peut intervenir à deux niveaux : dans la base de données elle-même, qui se trouve modifiée, ou lors de l’analyse.
Lorsque les données manquantes sont éliminées en amont, il est prudent de conserver une copie de la base initiale parallèlement à la version nettoyée.
Les logiciels de statistiques permettent aussi d’intervenir au moment de l’analyse, sur la base brute.
Le choix d’imputer la valeur manquante par une valeur renseignée revient alors à l’analyste. Mais la technique permettant de déterminer cette valeur fictive lui revient aussi. Et c’est là que les choses se compliquent, ou du moins, c’est là que l’analyste doit connaître son métier et le sujet sur lequel il travaille puisqu'il existe plusieurs techniques.
Pour les variables qualitatives, le choix est assez limité : la suppression pure et simple de la ligne ou le mode. Selon les logiciels, un algorithme peut aussi déterminer la valeur la plus probable compte tenu des variables renseignées (voir ci-dessous la méthode du plus proche voisin).
Pour les variables quantitatives, le choix est un peu plus large. Outre la suppression et le mode, il est souvent possible d’imputer la moyenne, ce qui est rarement une bonne idée. Cependant, des techniques d’analyse de données donnent souvent de bons résultats. Voyons par exemple quelles techniques sont proposées par XLSTAT pour modifier la base de données.
Exemple
Avec ce logiciel, si l’on clique sur « Préparation des données » puis « Données manquantes », une boîte de dialogue propose la méthode du plus proche voisin, l’algorithme NIPALS et l’imputation multiple.

La méthode des K plus proches voisins (KNN) est une classification supervisée surtout utilisée dans la reconnaissance de formes (notamment par les logiciels de retouche photographique). Si K = 1, c’est LE plus proche voisin qui est sélectionné. Les individus sont donc classés à partir de toutes leurs caractéristiques et si l’une d’elles manque, on lui impute celle de l’individu classé au plus près de lui.
L’algorithme NIPALS, élaboré par H. Wold en 1973, ne repose pas sur une classification mais sur une ACP. Là encore, l’idée est de trouver des individus qui ressemblent à celui dont il manque une information pour déterminer celle qui serait la plus probable.
L’imputation multiple basée sur les chaînes de Markov (MCMC) consiste à déterminer les paramètres d’une loi normale à partir des informations renseignées, puis à procéder à un tirage aléatoire de valeurs à partir de cette loi de probabilité. On remplace donc, dans un premier temps, les données manquantes par des valeurs aléatoires. Ensuite, une régression multiple est appliquée. La variable expliquée est celle qui n’est pas renseignée pour certains individus et les explicatives sont toutes les autres variables. Le modèle obtenu permet une seconde imputation. On peut ensuite faire tourner le modèle n fois et retenir finalement, pour chaque valeur manquante, la moyenne obtenue sur les n estimations.
Le tableau ci-dessous reprend des estimations de démographie publiées en 2015 pour l’année 2018.
| Pays | Taux de natalité | Taux de mortalité | Espérance de vie | Taux de mortalité infantile | Nombre d'enfant(s) par femme | Taux de croissance |
| Allemagne | 8,7 | 11,3 | 81,6 | 2,5 | 1,44 | -1 |
| Autriche | 9,7 | 9,5 | 82,2 | 2,5 | 1,53 | 2,4 |
| Belgique | 11,4 | 9,7 | 81,5 | 2,7 | 1,83 | 5,8 |
| France (métropolitaine) | 11,9 | 9,1 | 82,9 | 2,8 | 1,99 | 4,1 |
| Luxembourg | 11,5 | 7,1 | 82,4 | 1,3 | ? | 11,7 |
| Pays-Bas | 10,5 | 8,8 | 82,1 | 3 | 1,77 | 3 |
| Suisse | 10,5 | 8 | 83,7 | 3 | 1,58 | 8 |
L’espérance de vie pour la France, estimée à 82,9 ans, a été effacée. Elle est peut-être difficile à déterminer car elle est plutôt éloignée de la moyenne. Le logiciel trouvera-t-il une valeur proche ?
Tous les pays ont été pondérés de façon identique.
Avec la méthode du plus proche voisin, XLSTAT nous propose 81,5. Les tableaux de statistiques descriptives, avant et après traitement, ne sont pas reproduits ici.
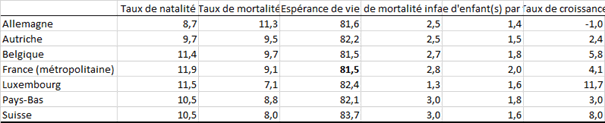
Avec NIPALS, le logiciel trouve 80,652 et avec l’imputation multiple (cinq imputations), un très honnête 82,522.
Nous avons réitéré l’essai en supprimant le nombre d’enfants par femme au Luxembourg, cette valeur (1,61) étant proche de la moyenne. Les résultats sont les suivants :
- Plus proche voisin : 1,99
- NIPALS : 1,7
- Imputation multiple : 1,737 (5 imputations) ou 1,716 (10 imputations).
Considérant la faible quantité sur laquelle s’appuient les analyses factorielles ou le modèle d’imputation multiple, les résultats semblent plutôt bon, en particulier ceux fournis par la dernière méthode.
