Statistique et test de Durbin-Watson (DW)
Tout petit déjà, vous souhaitiez savoir s’il existait une autocorrélation des résidus, notamment dans les modèles de prévisions. Eh bien en lisant cette page, vous saurez comment lever cette incertitude.
Utilité
Supposons que vous avez élaboré un modèle, par exemple de régression multiple et que vous le comparez ensuite aux données réelles qui ont permis de l'établir. Vous obtenez une série d’écarts. L’un des moyens de déterminer si le modèle est perfectible est de contrôler si deux écarts successifs se ressemblent (autocorrélation d'ordre 1). Voyons le comment et le pourquoi.
Le « comment » : soit votre logiciel favori vous restitue un graphique des résidus et vous remarquez que les points qu’ils représentent tracent une sorte de courbe, ce qui signifie qu’ils contiennent une information « oubliée » dans le modèle, soit vous établissez un test non paramétrique de Durbin-Watson afin de fonder votre opinion de façon quantifiée et non sur une visualisation.
Le « pourquoi » : le modèle est peut-être mal choisi (régression linéaire simple au lieu d’une régression sur tendance exponentielle ou polynomiale, par exemple). Souvent, l’autocorrélation s’observe sur les résidus d’une modélisation de série chronologique. Et là, si le type de modèle est bien choisi, de deux choses l’une : d’abord, il peut exister une véritable autocorrélation entre les observations, par exemple en raison de comportements qui ne changent pas brusquement. Le modèle est presque bon, il suffit d’ajouter la variable expliquée de \(n-1\) dans les explicatives de \(n\). En revanche, si aucune autocorrélation n'a de raison d'être, il faut chercher d’autres variables candidates.
Test
Maintenant que vous mourrez d’envie d’en savoir davantage sur ce fameux test de Durbin-Watson, voyons l’expression de cette statistique (\(e\) signifie résidu) :
\[DW = \frac{{\sum\limits_{i = 2}^n {{{\left( {{e_i} - {e_{i - 1}}} \right)}^2}} }}{{\sum\limits_{i = 1}^n {{e_i}^2} }}\]
Cette statistique, notée d ou DW, a une valeur comprise entre 0 et 4. Si elle est proche de zéro, l'autocorrélation est positive, les valeurs situées autour de 2 montrent une absence d’autocorrélation et si l’on s’approche de 4, il existe une autocorrélation négative (valeurs tantôt au-dessus et tantôt au-dessous de la tendance).
Pour une interprétation plus précise on se réfère à une table, à moins que le logiciel n’intègre un petit commentaire dans ses restitutions. On trouve rarement des tables qui donnent des valeurs en-deçà de 15, les conclusions n’étant alors pas très significatives.
La table comprend, en fonction du nombre de réalisations, deux limites entre lesquelles il y a un doute (\(d1\) et \(d2\), mais cette écriture n’est pas normalisée) :
![]()
En général, ces zones de doute sont considérées comme « probablement sans autocorrélation ».
Exemple
Prenons l’exemple réel d’une régression simple (les conclusions seraient les mêmes si la régression était multiple). Il s’agit du nombre hebdomadaire de pages vues au cours des quinze premières semaines d’existence de ce merveilleux site qu’est www.jybaudot.fr (la première semaine étant incomplète, les données commencent à 2 et se poursuivent jusqu’à 16). Source AwStats.
| Semaine | Pages vues |
| 2 | 763 |
| 3 | 1 432 |
| 4 | 2 724 |
| 5 | 2 956 |
| 6 | 3 198 |
| 7 | 2 775 |
| 8 | 1 528 |
| 9 | 1 756 |
| 10 | 2 720 |
| 11 | 2 708 |
| 12 | 2 822 |
| 13 | 2 824 |
| 14 | 3 112 |
| 15 | 3 796 |
| 16 | 3 943 |
On devine que la corrélation linéaire n’est pas bonne. Les semaines 8 et 9 correspondent en fait aux vacances d'hiver en France. Les sorties ci-dessous sont issues du logiciel XLSTAT d'Adinsoft (extraits).


Le tableau ci-dessous n’a pas été recopié complètement (les intervalles de confiance ne sont pas repris pour une regrettable raison de mise en page) :
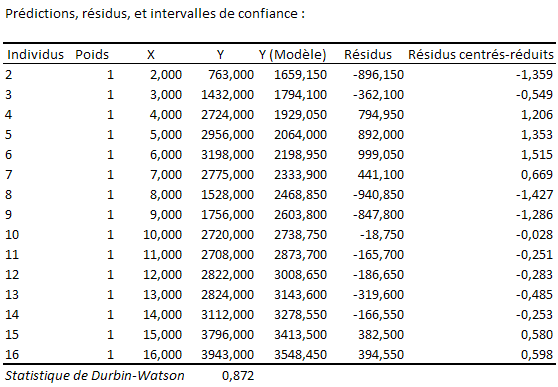
Que faisons-nous de ce DW égal à 0,872 ? Posons les hypothèses du test.
H0 : il n’y a pas d’autocorrélation d’ordre 1 entre les résidus. H1 : il existe un processus autorégressif d’ordre 1.

Le DW se situant entre 0 et 1,08, on rejette H0. Il se peut qu’il existe une autocorrélation positive d’ordre 1.
Voir aussi l'exemple de la page régression multiple avec tableur.
Ce test n’est pas celui qui emballe le plus les data analysts. La zone de doute, surtout, ne lui donne pas une grande crédibilité. Quand c’est possible, on a toujours intérêt à produire un corrélogramme pour compléter l'analyse d'autocorrélation.
