Cohérence du tidyverse
Dans le cadre de l’initiation à R, il nous a semblé qu’un exemple qui s’appuie sur plusieurs packages du tidyverse serait pédagogique…
Mais d’abord, une rapide présentation de readr.
readr
Le package readr appartient au tidyverse. Il est dédié à l’importation de données textuelles dans R.
Son objectif principal est de proposer une alternative moderne, rapide et cohérente aux fonctions historiques de base R comme read.csv() ou read.table().
La fonction la plus utilisée est :
read_csv("fichier.csv")
Elle permet d’importer un fichier CSV sous forme de tibble, c’est-à-dire une version modernisée du data frame.
readr présente plusieurs intérêts :
- syntaxe plus lisible,
- importation généralement plus rapide,
- meilleure gestion des types de variables,
- affichage plus clair des messages et des erreurs.
Par exemple, readr détecte automatiquement les nombres, les dates, les chaînes de caractères ou encore les valeurs manquantes. Dans l’exemple ci-dessous, nous demanderons une somme, ce qui sera possible puisque readr aura reconnu une variable numérique.
Outre read_csv(), il propose d’autres fonctions spécialisées :
- read_tsv() pour les fichiers tabulés,
- read_delim() pour les séparateurs personnalisés,
- write_csv() pour l’exportation.
readr s’intègre naturellement avec dplyr et ggplot2, ce qui en fait un point d’entrée fréquent dans les workflows du tidyverse.
En pratique, readr simplifie considérablement l’étape souvent délicate de l’importation des données.
Exemple
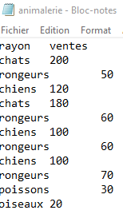
Une animalerie dispose d’un fichier tabulé avec des montants de ventes par rayon.

Importons les quatre packages qui nous servirons (nous pourrions aussi bien importer tout le tidyverse).
library(readr)
library(dplyr)
library(forcats)
library(ggplot2)
Première étape, lire le fichier :
vendus <- read_tsv("animalerie.txt")
Le fichier tabulé est à présent stocké dans l’objet vendus (nous avons préféré ne pas reprendre l’intitulé ventes pour éviter les confusions). Si on affiche celui-ci (instruction vendus), on constate que les colonnes sont parfaitement alignées.
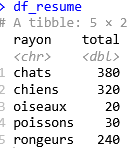
df_resume <- vendus %>%
group_by(rayon) %>%
summarise(total = sum(ventes))
Les fonctions group_by() et summarise() font partie du package dplyr. Nous avons créé un nouvel objet df_resume (df pour montrer qu’il s’agit d’un data frame).
On peut vérifier ce que R a produit avec la simple instruction df_resume. Affichage :
Trions par ordre décroissant des ventes (avec le package forcast).
df_resume <- df_resume %>%
mutate(
rayon = fct_reorder(rayon, total, .desc = TRUE)
)
C’est le même objet df_resume. Mais attention, si l’on affiche le résultat, on ne constate pas le tri ! Nous avons changé l’ordre interne des modalités du facteur rayon mais pas l’ordre des lignes du data frame ! L’effet apparaîtra ensuite, dans le graphique… Si toutefois on souhaite vérifier que le script était OK, on peut entrer levels(df_resume$categorie).
![]()
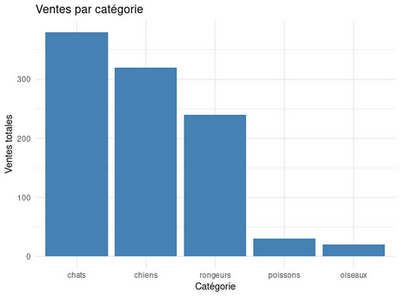
Produisons le graphique avec ggplot2 :
ggplot(df_resume, aes(x = categorie, y = total)) +
geom_col(fill = "steelblue") +
labs(
title = "Ventes par catégorie",
x = "Catégorie",
y = "Ventes totales"
) +
theme_minimal()
La dernière instruction, theme_minimal(), permet d’obtenir un graphique plus lisible que le thème par défaut (pas de fond gris, bordures allégées…).
Notez qu’on aurait pu regrouper les petits rayons en « Others ». Ainsi, si l’on ne souhaite individualiser que trois modalités…
vendus %>%
mutate(rayon = fct_lump(rayon, n = 3)) %>%
group_by(rayon) %>%
summarise(total = sum(ventes)) %>%
ggplot(aes(x = rayon, y = total)) +
geom_col()
Ici, c’est la présentation par défaut du diagramme en barre que nous avons choisie (à vous de le réaliser !)
