Analyse discriminante prédictive
L’analyse discriminante décisionnelle est un prolongement de l’AFD. Elle permet par exemple de « noter » la santé financière d’une entreprise grâce à une fonction de score.
Problématique
Petit rappel : l’AFD est une technique merveilleuse car elle permet, en fonction de plusieurs critères mesurés, de séparer au mieux le bon grain de l’ivraie, ou différentes maladies, ou toute autre partition dont on hésite sur les frontières. Si l’AFD peut être utile pour trouver des critères discriminants dans le cadre d’une approche globale, le fin du fin reste tout de même d’affecter une nouvelle variable à tel ou tel groupe sans trop de risque d'erreur. C’est le but du scoring, technique largement utilisée mais faisant curieusement l’objet de très peu d’ouvrages en langue française.
La problématique est donc la même que celle d’une régression multiple, sauf que la variable dépendante est qualitative et non quantitative. L’analyse discriminante peut être mise en concurrence avec la régression logistique.
Si l’on se place dans une optique prédictive, c’est que l’analyse a été réalisée sur un échantillon. On tentera donc de deviner dans quel groupe se situeront d’autres observations, existantes ou à venir, en déterminant une règle d’affectation. Exemple d’un score d’octroi : en vue d'acheter une voiture à crédit, vous devez remplir un questionnaire. Celui-ci est la partie émergée de la grille de score qui permettra de vous situer ou non parmi les clients qui ont du mal à rembourser le prêt, en extrapolant le comportement d’autres clients qui avaient le même profil que vous.
Toutefois, c'est davantage le scoring d'entreprise qui utilise l'analyse discriminante. Le scoring de particuliers se fonde plutôt sur la régression logistique, plus adaptée aux critères qualitatifs.
Comment faire ? D’abord, la sélection des variables. S’il s’avère que les données satisfont aux hypothèses de multinormalité et d’homoscédasticité, vous êtes sur la bonne page. L’analyse factorielle reste d’ailleurs robuste si ces hypothèses ne sont pas très bien vérifiées (mais en revanche sensible aux outliers). Si les variances sont très différentes, on utilise une approche bayésienne.
L'alternative est la suivante :
Première situation, celle de l’équiprobabilité. C’est la situation où, pour établir une grille de score d'octroi, on relève un même nombre de bons et de mauvais dossiers pour constituer l’échantillon d’apprentissage. Si les observations sont à répartir entre deux groupes seulement, la situation est simple.
Deuxième cas, les groupes ont des poids différents (exemple ci-dessous).
Validation
Une validation digne de ce nom s’effectue sur un échantillon ad hoc, qui n'exige pas un nombre d’observations aussi important que l’échantillon d’apprentissage, sur lequel on maintient les valeurs extrêmes, et qui comprend le même nombre d’observations d’une classe à l’autre (équiprobabilité) afin de pouvoir utiliser les outils d’évaluation.
Quels sont ces outils ? La matrice de confusion, la courbe ROC, l'indice de Gini et la courbe de lift. Le taux de bon reclassement sur l’échantillon d’apprentissage est restitué avec les autres sorties de l’analyse (voir ci-dessous).
Exemple
Voyons l’interprétation des résultats avec l’exemple de ce service de 26 collaborateurs, dont 11 ont demandé à la DRH leur mutation dans un autre service. Les variables d’âge, d’âge de fin d’études et d’ancienneté dans le poste sont-elles discriminantes pour permettre une distinction entre ceux qui souhaitent rester et les aventureux ?
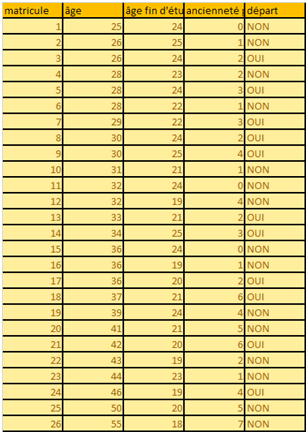
Les résultats ci-dessous ont été obtenus avec SPSS (quelques extraits seulement) et ne concernent pas la validation du modèle. L’option « all groups equal » a été cochée.
La valeur propre est de 0,349, ce qui n’est pas terrible… SPSS procède au test du lambda de Wilks (XLSTAT ajoute les traces de Pillai et de Hotteling-Lawley ainsi que la plus grande racine de Roy). En l’occurrence, le test confirme la piètre qualité de la discrimination.
Dans le champ d’une analyse prédictive, le tableau des coefficients de la fonction canonique est particulièrement utile puisque l’on multipliera les valeurs observées par ces coefficients pour obtenir la valeur de la variable canonique :
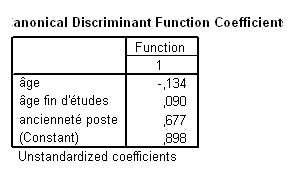
On obtient donc l’équation suivante :
Score \(=(-0,134 × \scr{âge})\) \(+\) \((0,09 × \scr{âge\; fin\; d'études})\) \(+\) \((0,677 × \scr{anc.})\) \(+\) \(0,898\)
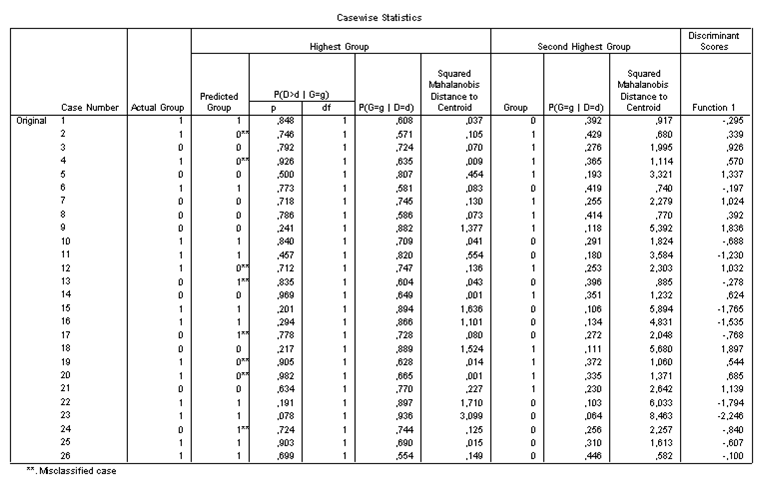
D’autres sorties établies à partir de cet exemple figurent sur la page du lambda de Wilks. On observe que huit observations ont été mal classées, ce qui confirme la piètre qualité de l’analyse.
Pour terminer, signalons l’existence d’une analyse discriminante quadratique qui ne nécessite pas d’homoscédasticité entre les différents groupes.
