Valeurs aberrantes et extrêmes
On peut toujours réaliser de longues études statistiques avec les méthodes les plus sophistiquées. Si les données comportent des anomalies, les conclusions de l'étude risquent de ne pas valoir grand chose. D'où l'importance d'un nettoyage des données.
Certes, des algorithmes complexes peuvent traiter des bases de données brutes, avec leurs erreurs et leurs valeurs aberrantes, dans une problématique de machine learning. On parle alors de deep learning. Mais généralement, l'étape du nettoyage des données est réalisée par un spécialiste (data analyt ou data scientist). C'est même l'étape la plus cruciale du processus d'analyse. En pratique, les petites bases sont souvent visualisées avec un tableur (une petite base peut comporter des dizaines de milliers d'enregistrements, tout dépend du nombre d'attributs).
Pourquoi d'étranges données ?
Il peut exister des individus qui présentent des aberrations au regard des caractères étudiés : les atypiques, les inclassables, les clients qui n’appartiennent à aucune catégorie identifiable, un guitariste de glam metal au conseil d’administration d’une banque d’affaires... Certes, pas toujours des individus inintéressants, mais ils sont les ennemis des techniques de statistiques et de data mining car ils peuvent impacter significativement les résultats.
Ces valeurs peuvent correspondre à un évènement : une absence de commandes pendant une période inhabituelle, une grève, une panique…
Elles peuvent aussi susciter d'intéressants questionnements. Par exemple, il existe un lien fort entre le PIB par habitant et le pourcentage de personnes en situation d'obésité. Mais il existe deux exceptions, le Japon et la Corée du sud.
Ces outliers sont des valeurs extrêmes, qui reflètent la réalité. Il convient d'en tenir compte et ils ont leur place dans l'analyse. Il ne faut pas les confondre avec les valeurs aberrantes, qui sont fausses et qu'il faut traiter. Ce sont des erreurs de saisie ou de calcul, des fausses déclarations, des mesures relevées par un matériel défectueux... C'est souvent un spécialiste du métier qui peut les détecter.
Traitement
Le traitement de ces valeurs particulières peut conduire à modifier la base de données brutes mais c'est souvent un jeu de données qui en est extrait qui est nettoyée des valeurs aberrantes.
Ce traitement fait partie du processus habituel de préparation des données (qui est toujours l'étape la plus longue du travail d’étude). Il est souvent plus long que celui des données incomplètes, quoique certains logiciels intègrent des algorithmes d’identification.
Gardez à l'esprit qu'il n'y a pas de règle absolue pour définir au-delà de quelle borne une valeur est considérée comme aberrante. Il s'ensuit qu'un jeu de données dépend de l'analyste qui l'a constitué.
Détection et application de méthodes adaptées
Parfois, la détection de valeurs extrêmes constitue l’objet même de l’étude (par exemple dans le cadre d’une lutte contre la fraude). Ce type d’étude est relativement facile à mener.
La détection de valeurs aberrantes peut quant à elle s’inscrire dans une démarche d’amélioration de la qualité, par exemple la fiabilité de la saisie des données. Il est certain que si le volume de données anormales est trop élevé, il faut revoir le système de collecte.
Pour les séries chronologiques, voir les valeurs extrêmes des chroniques.
Détection automatique : selon les logiciels, elle peut permettre à l'analyste de les repérer pour un traitement au cas par cas (par exemple sur Statgraphics Centurion : « Identification des points extrêmes »...) ou, si le volume de données est très important, de choisir un traitement global.
La méthode de l'intervalle de confiance : si les valeurs observées suivent une loi normale, on peut considérer comme aberrantes ou extrêmes celles qui se situent au-delà de x écarts-types autour de la moyenne. Il est toutefois préférable d'éliminer d'abord les valeurs trop extrêmes et manifestement fausses qui pourraient conduire à un écart-type anormalement élevé.
Détection visuelle : à moins d'analyser du big data, il est courant de visualiser les données brutes avec un tableur.
Les données quantitatives sont alors faciles à explorer. D'abord, vous pouvez connaître le minimum et le maximum d'une colonne de nombres. Cette opération très rapide peut suffire lorsqu'il n'y a aucune valeur aberrante.
Dans un souci de clarté, ouvrez un nouvel onglet dans lequel figureront les valeurs minimales et maximales. Il suffit d'entrer les fonctions MIN et MAX et de sélectionner toute la colonne du jeu de données (intitulé compris, votre tableur comprend très bien que ce n'est pas une valeur).
Par exemple, dans la première feuille Excel se trouvent les données :
Et dans la seconde feuille...
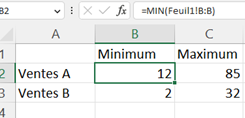
Si ces valeurs extrêmes sont considérées comme aberrantes, il faut creuser pour savoir s'il y en a d'autres.
Pour cela vous pouvez trier chaque colonne de valeurs numériques les unes après les autres. En observant le haut et le bas vous avez une idée du nombre d'aberrations. Vous pouvez complétez votre exploration avec une identification sur graphique (courbe ou nuage de points, en général).
Il peut être plus compliqué de détecter un outlier quand ce n'est pas l'un de ses attributs qui pose problème mais la réunion de plusieurs d'entre eux. Par exemple, il n'est pas aberrant d'avoir 80 ans ni d'être salarié, mais il n'est guère possible, du moins en France, de présenter ces deux caractères à la fois. Cette étrangeté apparaît si l'on poursuit l'étude avec une analyse multivariée, de type analyse factorielle.
Lorsque ce sont des données alphabétiques qui sont fantaisistes, de petits programmes permettent de les repérer (par exemple, des numéros de téléphone 01 00 00 00 00).
Robustesse de la technique
Il est parfois habituel de rencontrer des valeurs extrêmes et il n'est pas question de les traiter. En revanche, on adapte l'outil d'analyse.
Prenons le cas le plus simple, celui d’une série univariée. Que signifie la moyenne s’il existe un ou quelques outliers ? Rien. C’est le cas lorsqu’on analyse un ensemble de rémunérations. Et c’est pourquoi on retient dans ce cas la médiane comme indicateur de position centrale plutôt que la moyenne.
Prenons maintenant le cas d’une régression linéaire simple. Nous savons tous qu’une valeur anormalement basse ou élevée peut modifier parfois de façon très sensible la pente de la droite de régression qui résume le nuage de points. Il existe alors des alternatives robustes aux outliers (méthode de Theil, par exemple).
Lorsqu'il n’existe pas d’issue de secours dans le choix des méthodes (ce qui est tout de même le cas le plus courant), on s’attaque aux données…
Elimination ou imputation ?
Si les données sont nombreuses, les unités statistiques qui présentent des valeurs aberrantes ou extrêmes sont en principe éliminées sans pitié. Il est toutefois judicieux de se constituer un fichier des éliminés : une observation rapide permet parfois de découvrir certaines inepties récurrentes, par exemple dues à des erreurs de saisie, et un traitement ad hoc plus ou moins automatisé permet de rétablir des informations sûres, soit dans la base de données elle-même, soit dans la base de travail. Dans le champ des analyses multivariées, il est souvent possible de ne retenir que les valeurs « correctes » d’une observation, celles qui présentent des valeurs extrêmes peuvant être incluses comme « illustratives ».
L’imputation consiste à quant à elle à remplacer les valeurs aberrantes, extrêmes ou manquantes par d’autres. La winsorisation est une technique efficace de traitement des valeurs extrêmes : on positionne une limite sur des quantiles, par exemple le premier et le 99e centile, puis on affecte ces valeurs-ci à celles qui se situaient en-dehors de l'intervalle. En revanche, l’idée d’une imputation par valeur moyenne est rarement bonne !
La méthode de l’intervalle de confiance évoquée plus haut permet soit l’élimination, soit l’imputation par les bornes de l’intervalle.
Enfin, les valeurs manquantes peuvent elles aussi conduire soit à éliminer des observations, soit à procéder à des imputations.
