Modèles de régression simple
La régression est une technique statistique de base, extraordinairement féconde pour de nombreuses sciences et techniques. Elle consiste à faire apparaître un lien entre une ou plusieurs variables quantitatives, dites « explicatives » (bien que parfois elles n’expliquent rien) et une variable quantitative « expliquée » au sein d’un échantillon ou d’une population.
Lorsque plusieurs variables interviennent, on parle de régression multiple. Nous ne développerons pas ce sujet ici. Notez que ce type d’analyse peut s’accommoder de variables qualitatives. Lorsqu’on met en rapport deux variables seulement, on parle de régression simple. Nous nous cantonnerons donc à la simplicité et nous ne développerons pas non plus aspects théoriques. Si ceux-ci vous intéressent, nous vous invitons à explorer l’index statistique de ce site.
Historique
Situons-nous à une période charnière, fin dix-neuvième début vingtième, en Angleterre. C’est là que les statistiques mathématiques ont explosé sous l’impulsion de quelques brillants esprits. Aucune découverte dans ce domaine n’est ensuite venue révolutionner le corpus établi à cette époque.
Le pionnier fut certainement Francis Galton (1822-1911). Cousin de Darwin, inventeur du sac de couchage, Galton cherchait surtout les moyens d’améliorer l’espèce humaine (c’est d’ailleurs à lui que nous devons le terme d’eugénisme en 1883). Ce projet, qui aujourd’hui paraît à tous comme étant une monstruosité, rencontrait alors un large écho, notamment chez les premiers statisticiens.
Aujourd’hui, les lycéens connaissent de Galton sa planche qui permet d’introduire les probabilités indépendantes. Ils savent moins qu’il est à l’origine d’un apport fondamental à la science : la régression.
Pourquoi ce nom étrange ?
Galton étudia la taille d’individus et de leur descendance. Il constata que si les parents sont grands, leurs enfants le sont souvent. Même remarque pour les petites tailles. Cependant, il existe des limites : si les parents ont une taille extrême, dans un sens ou dans l’autre, leurs enfants se rapprochent plus ou moins de la moyenne.
Ce phénomène apparaissait comme une régression pour les eugénistes qui imaginaient une Angleterre peuplée de géants au Q.I de génie.
Remarquons que chacun peut observer l’existence de limites biologiques. Parmi les espèces animales qui ont fait l’objet d’une sélection millénaire, ce sont les chiens qui présentent la plus grande variabilité de taille. Malgré cela, on n’a jamais vu de chihuahua de la taille d’un hamster ni de dogue allemand grand comme un cheval…
Bref, Galton trouva une relation affine entre la taille du père (variable explicative) et celle de ses enfants (variable expliquée par la précédente).
Mais une liaison peut être de plus ou moins marquée. C’est Karl Pearson qui, après avoir inventé l’écart-type, lui trouva une application dans sa formule du coefficient de corrélation. Plus ce dernier est proche de zéro, plus la liaison entre les deux variables est faible tandis que s’il est proche de -1 ou 1, elle est très forte.
Un vaste choix
Graphiquement, les observations prennent la forme d’un nuage de points. En abscisse figure la variable explicative et en ordonnée la variable expliquée.
La régression consiste à résumer ce nuage au mieux, soit par une droite soit par une courbe dont on détermine l’équation. En d’autres termes, on établit l’expression mathématique d’une fonction qui peut, à condition que la qualité de la régression soit bonne, permettre des prévisions (si la variable explicative est le temps) ou des prédictions.
Sur ce site, nous présentons différents cas de figure et des exemples de détermination « manuelle » de ces équations. En pratique, courbes et équations sont réalisées en un clin d’œil par bon nombre de logiciels, y compris des tableurs, ou par des calculatrices telles que celles utilisées au lycée.
Le statisticien intervient surtout dans le choix du modèle : vers quel type de régression s’orienter en fonction de la forme du nuage à ajuster ? C’est ce que nous allons voir ici. Précisons que le choix est parfois très difficile et qu’il faut davantage se fier à son bon sens qu’à une très bonne corrélation.
La régression linéaire est la plus simple. En fait, la droite de régression ne s’apparente pas à une fonction linéaire mais affine (il est toutefois possible avec certains logiciels et calculatrices de « forcer » une régression pour obtenir une équation de type \(y = ax.\)
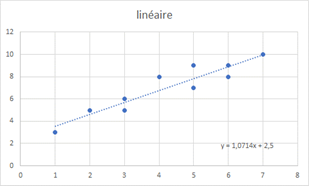
Une régression polynomiale de degré 2 (ou quadratique) s’applique à un nuage résumable par une portion de parabole. Les logiciels peuvent aller au-delà du degré 2. Par exemple, une calculatrice TI-83 permet des régressions jusqu’au degré 4 et Excel jusqu’au degré 6. Toutefois, il faut éviter de chercher des modèles trop sophistiqués qui résument très bien un nuage d’observations issues d’un échantillon mais qui s’avèrent souvent inefficaces dans une démarche prédictive.
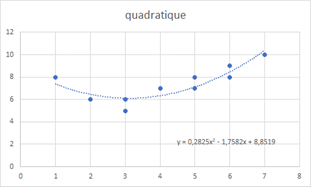
Le choix d’un degré 2 permet de modéliser certaines relations non monotones mais il ne signifie pas forcément un point de retournement (voir l’exemple d’ajustement quadratique).
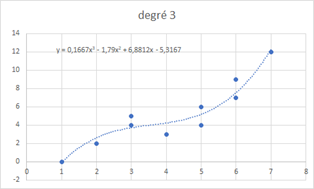
Exemple de régression sur tendance polynomiale de degré 3 :
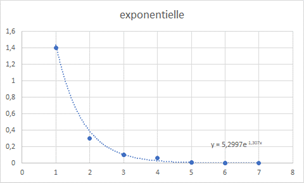
L’ajustement sur tendance exponentielle couvre deux cas de figures. Celui qui vient naturellement à l’esprit est celui d’une exponentielle positive (exemple en page de régression sur tendance exponentielle). Mais dans une problématique prévisionnelle, ce type de modèle est à manier avec beaucoup de précautions. Comme dit le dicton boursier, « les arbres ne montent pas jusqu’au ciel ». Le cas de l’exponentielle négative, comme ci-dessous, n’est guère adaptée à un modèle prévisionnel pour la raison inverse (prévisions pouvant être établies sans modèle !).
Une régression logarithmique modélise une évolution d’abord rapide, ensuite plus lente mais qui ne plafonne pas.
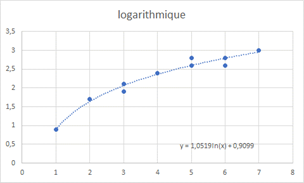
Cette configuration est proche d’un ajustement sur racine carrée (voir les ajustements non linéaires). S’il est prévisionnel, il peut être intéressant d’imaginer les possibilités à long terme pour choisir entre les deux. Là encore, la connaissance du sujet à traiter est fondamentale.
Les courbes en S sont particulièrement utiles. Là encore, il existe plusieurs modèles concurrents et il n’est pas toujours facile d’en privilégier un plutôt qu’un autre. Voir la régression sur tendance logistique et les courbes de Gompertz.
Mentionnons enfin les ajustements sur courbes sinusoïdes et sur fonctions puissances (non décrites sur ce site).
