Coefficient de Pearson entre v.a
Habituellement, on fait connaissance avec le coefficient de corrélation linéaire dans un cours de statistiques descriptives. Si toutefois on considère que les observations sont des réalisations de variables aléatoires (v.a) dont la distribution est supposée connue, ce même coefficient (« même » car il se calcule de la même façon) devient lui aussi une v.a dont on peut tester la validité.
Le coefficient
Note préalable : en page corrélation linéaire de variables statistiques nous l’avons nommé \(r\). Afin de bien marquer la différence méthodologique du coefficient considéré comme v.a, nous le nommerons \(\rho\) (la lettre grecque rhô).
On souhaite mesurer l’intensité d’une liaison linéaire constatée entre deux v.a \(X\) et \(Y\). Cette mesure est réalisée grâce à un indicateur sans dimension, rapport entre la covariance de \(X\) et \(Y\) sur le produit de leurs écarts-types. \(\rho = \frac{{{\sigma _{XY}}}}{{{\sigma _X}{\sigma _Y}}}\).
Ce coefficient est très souvent calculé à partir de données d’échantillon, qui se traduisent par des écart-types sans biais, dont le calcul est légèrement différent de l’écart-type statistique. Dans la mesure où cette différence n’apparaît qu’au dénominateur de la formule de la covariance et au dénominateur de celle du produit des écarts-types, il est rigoureusement identique d’utiliser la formule avec biais ou sans biais pour le calcul du coefficient de corrélation.
Le coefficient de détermination, qui indique la part de la variance expliquée par le modèle de régression linéaire, est le carré du coefficient de corrélation.
Quant au cube de notre coefficient, il est égal au rapport du coefficient d’asymétrie de Fisher de \(Y\) par rapport à celui de \(X\). Il indique quelle est la part d’asymétrie expliquée par le modèle.
\(\rho\) est toujours compris entre -1 et 1. Lorsqu’il est nul, l’indépendance linéaire est totale. Au contraire, s’il est égal à -1 ou à 1, il existe une liaison parfaite (fonction affine). Le coefficient directeur de la droite d’ajustement est du signe de \(\rho\).
Attention, le coefficient de corrélation linéaire n'est pas un indicateur robuste. Il faut s'assurer que les données ne contiennent pas de valeurs aberrantes ou, le cas échéant, savoir comment les traiter (voir les pages outliers et outliers dans les séries chronologiques).
Précisons que l’utilisation du coefficient de corrélation ne se limite pas à l’étude de lien entre deux v.a seulement. On peut l’utiliser sur \(n\) variables grâce aux matrices de corrélation. Les éléments de ces matrices carrées symétriques sont les coefficients calculés sur toutes les v.a prises deux à deux. Voir aussi la page corrélation partielle.
Validité
\(\rho\) étant une variable aléatoire, sa validité dépend de l’effectif \(n\) sur lequel il a été établi.
Plus précisément, c’est le nombre de degrés de liberté (\(n - 2\) pour une régression simple), qui détermine une valeur limite, pour un niveau de risque d’erreur donné, et il existe pour cela des tables du \(\rho\). Elles sont rarement reprises dans les manuels de statistiques (voir tout de même G. Saporta, Probabilités, analyse des données et statistique, Technip : table jusqu’à 200 degrés de liberté). En revanche, on peut construire une statistique avec \(\rho\) et la comparer avec un \(t\) de Student :\[t = \frac{{\left| \rho \right|}}{{\sqrt {\frac{{\left( {1 - {\rho ^2}} \right)}}{{n - 2}}} }}\]
On procède également au test du \(F\) à partir du coefficient de détermination.
Cas particulier
La suite de coefficients de corrélation d’une série chronologique avec elle-même selon un décalage de \(k\) (\(k = 1, 2, \) etc.), c’est-à-dire la suite des coefficients d’autocorrélation, s’appelle une fonction d'autocorrélation, visualisable sur un corrélogramme.
Exemple
Avec Statistica : pour une étude de marché, on demande à vingt répondants de noter un produit sur 4. On veut savoir si leur âge peut expliquer une perception différente de ce produit. Nous ne disposons que de tranches d’âge et nous utiliserons les centres de classes.
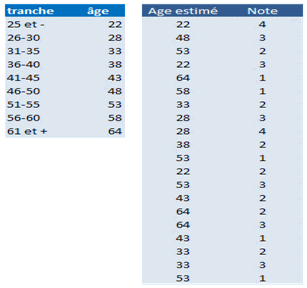
Les sorties de la régression sont les suivantes (extrait) :
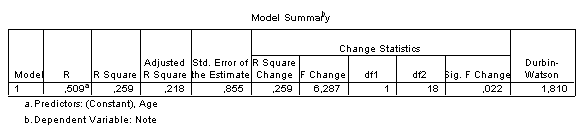
Pour un niveau de confiance de 0,95, le coefficient de 0,509 est significatif puisqu’il est supérieur à 0,44 (18 degrés de liberté). Mais la régression n’explique que très moyennement la dispersion : le \(R^2\) est de 0,259. La variance totale n’est expliquée qu’à \(25,9\,\%\) par la régression linéaire. Le \(R^2\) ajusté s’établit à 0,218.
Dans la mesure où la corrélation semble couci-couça, il aurait été intéressant de relever le véritable âge des répondants, ce qui aurait peut-être fait basculer nos conclusions d’un côté ou de l’autre.
