Conformité d'une moyenne sur petit échantillon
Notre tâche est ici de comparer la moyenne relevée sur un petit échantillon (< 30) à un standard (ou norme) mais rien n’interdit d’utiliser la méthode pour des échantillons plus grands (exemples ci-dessous). Si votre logiciel vous le permet, les résultats n’en seront que plus fiables.
Le cas est fréquent, notamment pour évaluer la qualité d’une production : un cahier des charges impose un diamètre de \(x,\) on relève une moyenne un peu différente sur un échantillon aléatoire de \(n\) pièces et l’on souhaite savoir si la norme est malgré tout considérée comme respectée sur l'ensemble de la production.
Test
On utilise pour cela un test. Dans cet exemple, le test est bilatéral car le diamètre ne doit pas s'écarter de la norme d’un certain pourcentage, ni dans un sens ni dans l’autre. En revanche, si le test porte sur la durée de vie d’une ampoule, il est unilatéral : tant mieux si la durée de vie est plus longue qu’annoncé, l’essentiel est qu’elle ne soit pas inférieure à une certaine marge au-dessous de la durée prévue, provoquant l'ire des associations de consommateurs.

La validité du test repose sur l’hypothèse de normalité. Dans l'exemple des ampoules, on suppose que les durées de vie moyennes observées sur de nombreux échantillons suivraient une loi normale distribuée autour d'une espérance inconnue. C’est le cas lorsque les échantillons eux aussi présentent une distribution normale (mais pas obligatoirement, Cf. le théorème central-limite). Des tests de normalité permettent de vérifier cette hypothèse. Par ailleurs, on fixe un intervalle de confiance, qui correspond à la moyenne observée, ou empirique, (estimateur de l'espérance) plus ou moins une certaine marge due à l’échantillonnage.
Bref, on mesure une moyenne et un écart-type sur un échantillon de taille \(n.\) Si l’on s’est fixé comme standard \(m,\) nous nous intéressons à la variable aléatoire \(t\) qui se présente ainsi :
\[t = \frac{\overline{x} - m}{\frac{s'}{\sqrt{n}}}\]
\(s'\) est l’écart-type sans biais. Le dénominateur représente donc l’écart-type attendu des moyennes observées et c’est par rapport à cette dispersion qu’il faut mesurer l’écart entre la norme et la moyenne relevée sur notre échantillon. Cette démarche vous semble logique, non ? Ce \(t\) suit une loi de Student à \(n - 1\) degrés de liberté (ddl). Les logiciels vous dispensent d’aller dépoussiérer la table de Student mais vous pouvez construire vous-même cette dernière avec des ddl et des risques d'erreur sur-mesure grâce au mode d'emploi en page de table de Student, au cas où.
Exemple
Exemple, en utilisant XLSTAT. On calcule sur trois échantillons une même moyenne de 6,7. Acceptant un risque d’erreur alpha de \(5\,\%,\) ce chiffre est-il différent d’un standard de 6 ? Hypothèse H0 : la différence entre 6,7 et 6 est due à une fluctuation d’échantillonnage. Hypothèse alternative H1 : faut pas exagérer, 6 et 6,7 n’ont rien à voir.

Le premier échantillon est minuscule : effectif de 10, écart-type sans biais de 1,64. Le logiciel sort l’état suivant :
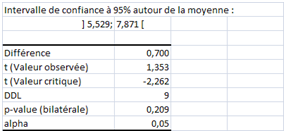
La valeur critique de 2,262 est celle qu’on lit dans la table du \(t.\) La p-value est de \(20,9\,\%.\) Conclusion : la norme 6 se situe dans l’intervalle de confiance. La moyenne observée est conforme avec un risque de se tromper inférieur à \(5\,\%.\) L’écart n’est pas significatif.
Le deuxième échantillon est cinq fois plus grand mais l’écart-type reste proche (1,61). Les risques de fluctuation sont donc moindres et le test sera d'autant plus « sévère ».
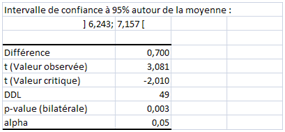
Et voilà : la p-value est inférieure à 0,05, il faut considérer que la moyenne obtenue est bien différente de 6 !
Petite remarque en passant : l’effectif est déjà grand (supérieur à 30) et la loi de Student peut être approchée par la loi normale ce qui revient à utiliser le test \(z\). Dans le cas d’un test bilatéral, on utilise alors la valeur 1,96 comme coefficient multiplicateur de l’indicateur de dispersion autour de la moyenne empirique afin d'obtenir l’intervalle de confiance. Ici, l’écart-type divisé par la racine carrée de l’effectif est égal à 0,2272. La fourchette haute, par exemple, est donc environ égale à \(6,7 + (0,2272 × 1,96)\) \(=\) \(7,145,\) ce qui est assez proche de la valeur indiquée ci-dessus par XLSTAT (7,157).
Maintenant, le troisième échantillon : même effectif, même moyenne, mais une dispersion beaucoup plus forte : écart-type = 12,17. Ce qui nous donne :
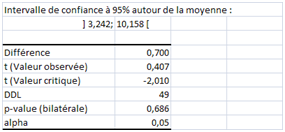
Avec une dispersion pareille, retour à la situation d'une moyenne proche du standard. Remarquez l’amplitude de l’intervalle de confiance autour de 6,7 : on accepterait même 10 comme valeur « peu différente » ! Autant dire que notre magnifique test a davantage sa place dans la corbeille à papier que sur le bureau du responsable de la qualité…
Note : la distribution de ce troisième échantillon n'est manifestement pas normale, ce qui ne gêne pas la démonstration mais évitez de faire des tests de Student sur ce type de distribution lorsque l’effectif est faible. Cela dit, les moyennes relevées plusieurs échantillons ayant le même effectif et la même variance que celui-ci peuvent très bien, quant à elles, suivre une loi normale, on ne sait jamais…
Si l’on acceptait un risque d’erreur de seulement \(1\,\%,\) ce serait bien sûr au prix d’une région d’acceptation plus importante.
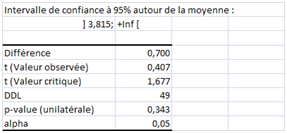
Nous avons vu comment impactent la taille de l’échantillon et la dispersion dans le cas d’une comparaison bilatérale (two-sided) avec une norme fixée a priori. Qu’en serait-il en cas de test unilatéral (one-sided) ? La région critique serait d’un seul tenant. Sur le troisième échantillon, si la norme 6 est un minimum, on ne rejette évidemment pas H0 puisque 6,7 est supérieur (test unilatéral à gauche) :
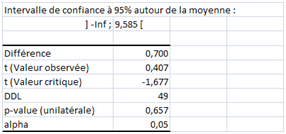
Plus intéressant, le test à droite (H0 : moyenne observée inférieure à 6) est positif également :