Lissage exponentiel simple (LES)
Lissage exponentiel : qui se cache derrière ce nom savant ? Une technique en réalité très simple de prévision à \(t + 1.\) Elle s’applique à des séries chronologiques sans tendance. Le principe consiste à donner plus d’importance aux dernières observations. On ne prolonge pas une série comme on le ferait, par exemple, avec une régression simple mais on cherche à obtenir une valeur lissée en \(t\) pour la reporter tout simplement en \(t + 1.\)
Une grande famille
Cette technique est très utilisée, notamment en gestion de stocks quand il existe un très grand nombre de références, beaucoup moins en prévision des ventes où on lui préfère le lissage exponentiel double, et surtout le lissage de Holt et le lissage de Winters. Elle est plus réactive que les moyennes mobiles ou les modèles utilisant la régression car elle prend rapidement en compte une modification de tendance. Elle est aussi utilisée dans le cadre de l'analyse technique pour prévoir les cours de bourse mais elle est alors connue sous le nom de moyenne mobile exponentielle (MME).
Formules de calcul
Une formule est la suivante : \(\hat{y}_t\) \(=\) \(\alpha y_t + (1 - \alpha )\hat{y}_{t-1}\)
Le coefficient \(\alpha ,\) compris entre 0 et 1, s’applique à la dernière réalisation. C’est la constante de lissage (ou coefficient de lissage) que l'on s'est choisie. Évidemment, si elle est égale à 1, on ne fait que reporter en \(t + 1\) l’observation de la période \(t.\)
Le coefficient \(1 - α\) s’applique quant à lui à la prévision précédente… qui ne s’est probablement pas réalisée (que l’art de la prévision est difficile !…).
Cette formule est un peu déstabilisante puisque t est le moment où la prévision a été établie et non celui où elle doit se réaliser. Ceci n'est pas gênant dans la mesure où l'on reporte en \(t + 1\) une valeur obtenue pour \(t.\)
Par exemple, pour prévoir une valeur de février, on additionne une proportion de la réalisation de janvier à la proportion complémentaire de ce qui avait été prévu pour janvier.
En pratique, l’algorithme de calcul est basique puisque, en transformant la formule ci-dessus, on constate que la prévision que l’on établit pour la date ou la période \(t\) est égale à celle de \(t - 1\) à laquelle on ajoute l’erreur de prévision \(e_t\) que multiplie \(α.\) Formule récurrente, donc, et bien pratique lorsque l’ordinateur gère en permanence des dizaines de milliers d’articles…
\(\hat{y}_t = \alpha e_t + \hat{y}_{t-1}\)
La démonstration est très simple. Il suffit de développer la première formule puis de factoriser par \(α.\)
Si vous avez l’impression que l’on marche sur la tête en se basant sur des erreurs pour prévoir l’avenir, la formule suivante vous paraîtra plus logique, bien qu’elle revienne au même :
\(\hat{y}_t \) \(=\) \(\alpha y_t\) \(+\) \(\alpha (1 - \alpha)y_{t-1}\) \(+\) \(\alpha(1- \alpha)^2 y_{t-2}\) \(+\) \(\alpha (1 - \alpha)^3 y_{t-3}...\)
En choisissant \(α = 0,3,\) la dernière valeur observée est donc pondérée à \(30\,\%,\) la précédente à \(0,3 × 0,7 = 21\,\%,\) celle d’avant à \(14,7\,\%\) et ainsi de suite jusqu’au début de la série (ce n’est évidemment pas cette formule que l’on s’amuse à programmer !). L'un des avantages de cette troisième présentation est de comprendre pourquoi on appelle ce lissage EXPONENTIEL (décroissance exponentielle des pondérations en remontant dans le temps).
Enfin, il est évident que la prévision n'a pour horizon que \(t + 1.\) Toutes les prévisions à horizon plus lointain seraient exactement les mêmes...
Quelques détails techniques restent à régler.
La prévision initiale
En raison de la formule récurrente du LES, on est obligé de choisir une valeur à partir de laquelle les prévisions seront effectuées. Cette valeur a peu d’importance si la série est longue. On prend souvent la moyenne des deux ou trois premières valeurs observées mais ce choix reste arbitraire. Les logiciels non spécialisés en prévision utilisent la première valeur.
Le choix de la constante de lissage
Elle peut être choisie par le prévisionniste mais en principe c'est un logiciel qui s'en occupe... Voir le choix de la constante du LES.
Et en cas de saisonnalité ?
Le LES appliqué tel quel donne des résultats aberrants. Il convient dès lors d'estimer empiriquement la tendance et la saisonnalité, additive ou multiplicative. La procédure consiste à prolonger la tendance par LES puis à réintroduire la saisonnalité.
Par ailleurs, la prévision est structurellement sous-estimée si la tendance est croissante et surestimée si elle est décroissante.
Exemple
L’utilitaire d’analyse d’Excel propose un lissage exponentiel où le « paramètre de lissage » demandé n’est pas \(α\) mais \(1 - α.\) Comme il est aussi facile et plus clair d’entrer les formules soi-même, le tableau suivant est « cousu main » :
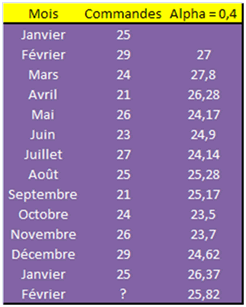
La série a été initialisée à 27, moyenne des deux premières valeurs observées (l’utilitaire d’analyse aurait obligatoirement choisi la première valeur). Le nombre de commandes prévu pour le second mois de février est estimé à :
\(25,82\) \(=\) \((0,4 × 25) + (0,6 × 26,37),\) soit 26 commandes (application de la première formule)
... ou \(25,82\) \(=\) \(0,4(25 - 26,37) + 26,37\) si l'on préfère utiliser la deuxième formule...

Autres utilisations
Mentionnons une autre utilisation du LES : dans une entreprise, il est souvent plus fiable et plus pratique d’établir des prévisions de volumes de ventes sur un marché global et non par produit, par exemple à l’aide d’une régression multiple. Ensuite, le prévisionniste doit trouver comment répartir chaque produit à l’intérieur de la prévision globale. Les volumes lissés peuvent alors constituer une bonne clé de répartition…
Enfin, le lissage exponentiel peut servir à détecter les valeurs aberrantes ou extrêmes.
