Théorème de König et propriétés de la variance
Une page un peu théorique mais qui vous donnera un aperçu des nombreuses vertus de la variance, ingrédient de base de nombreuses potions élaborées dans l’antre du statisticien…
Il existe deux versions heureusement très proches de la variance, indicateur de dispersion d'une variable aléatoire ou d'une variable statistique autour de sa moyenne, selon que l’on se situe dans le cadre de l’estimation ou dans celui des statistiques descriptives.
Présentation et théorème de König-Huygens
La variance d’une série de valeurs est la moyenne des carrés des écarts à la moyenne, soit :
\(\displaystyle{V = \frac{1}{N} \sum_{i=1}^N {(x_i - \overline{x})^2}}\)
Rejetant toute originalité, nous avns nommé \(N\) le nombre d’unités statistiques.
Concrètement, cette formule peut être explicitée par le tableau Excel ci-dessous. Soit un créateur de rosiers qui souhaite mettre sur le marché une nouvelle variété. Un des critères de qualité est que les nombre de fleurs soit à peu près homogène pour chaque pied. Notre créateur calcule manuellement la variance du nombre de roses le même jour sur quinze pieds différents.

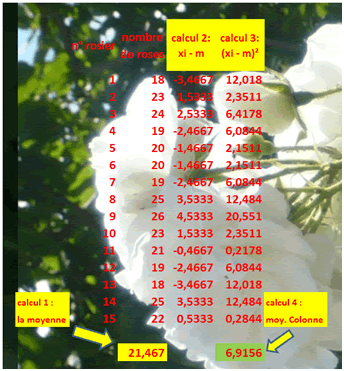
Ce résultat de 6,9156 n’est pas directement exploitable par notre créateur (au contraire de l'écart-type) mais tenons-nous ici au simple calcul de la variance. Ce calcul peut être réalisé d’une autre façon (oui, d'accord, avec une calculatrice, mais vous êtes sur une page de théorie !). Cette autre façon, beaucoup plus pratique, utilise le théorème de König (ou Koenig) : la moyenne des carrés moins le carré de la moyenne, soit...
\(\displaystyle{V = \frac{1}{N} \sum_{i=1}^N {x_i^2 - \overline{x}^2}}\)
Les mêmes données présentées selon ce principe :
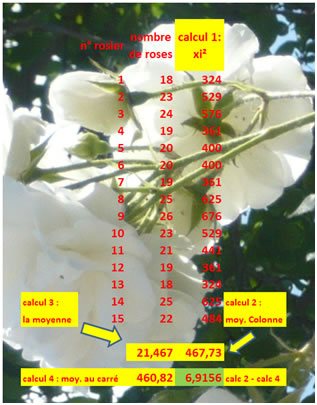
Si vous êtes intéressé, vous trouverez une démonstration facile du théorème de König en page d'initiation aux paramètres de dispersion et une autre en page de moments.

Voyons à présent d'autres propriétés...
Transformation linéaire
Propriété : \(V(aX + b) = a^2V(X)\)
La démonstration se trouve en page de transformation affine d'une variable aléatoire.
La constante \(b\) ne compte pas, la variance entre les valeurs 10 010, 10 020 et 10 030 étant la même qu’entre 10, 20 et 30, c’est-à-dire 66,67. Ce résultat est aussi égal à \(10^2\) fois la variance entre les valeurs 1, 2 et 3.
Variance d’une somme
La formule a des faux airs d’identité remarquable :
\(V(X+Y)\) \(=\) \(V(X) + V(Y) + 2{\rm{Cov}}(X,Y)\)
Si les variables \(X\) et \(Y\) sont indépendantes, la covariance est nulle et la formule devient on ne peut plus simple. Le cas est très fréquent puisqu’on le rencontre chaque fois qu’on procède à une régression simple ou multiple où la variance totale est décomposée en une variance expliquée par le modèle de régression et une variance résiduelle (dispersion inexpliquée des points autour de la droite de régression, voir page coefficient de détermination).
Ces deux propriétés peuvent bien entendu être combinées. Soit par exemple une variable aléatoire qui est une combinaison linéaire de deux autres : \(Z = aX + bY.\) Comment pourrait-on écrire l’écart-type de \(Z\) ?
Rappelons la formule du coefficient de corrélation linéaire :
\(\displaystyle{r = \frac{\sigma_{xy}}{\sigma_x \sigma_y}}\)
La covariance peut donc s’écrire \(rσ_x σ_y.\)
L’écart-type de \(Z\) peut se décomposer ainsi :
\(\sigma_2\) \(=\) \(\sqrt{a^2\sigma_X^2 + b^2 \sigma_Y^2 + 2rab \sigma_X \sigma_Y}\)
Voir une application pratique de cette formule, entrée dans un tableau Excel, avec l'exemple de frontière efficiente (si vous n'êtes pas réfractaire à la finance).
Sur un thème voisin, voir les contributions à la variance.
