Opérateurs retard et de différenciation
L’objectif de cette page n’est pas très ambitieux. Il consiste à présenter deux opérateurs utilisés dans le cadre de certaines techniques prévisionnelles.
L’opérateur retard (ou de recul, ou de rétro-décalage)
Il est sobrement dénommé \(B\) (comme Backward), parfois \(L\) (comme Lag). S’il n’est pas indispensable de le connaître pour se lancer dans de savantes prévisions, il reste pratique pour synthétiser les formules. Sa mission est la suivante : \(By_t = y_{t-1}.\)
On ne peut pas dire que c’est compliqué.
Ce qui est épatant, c'est qu'il est possible d'appliquer à cet opérateur de nombreuses propriétés algébriques. Par exemple, on l'affuble d'une « puissance » comme on le ferait à un nombre ou à une variable, c’est rigoureusement le même principe : \(B^2y_t = B(By_t).\)
De même, l'identité remarquable \((1 - B)^2y_t\) \(=\) \(y_t - 2y_{t-1} + y_{t-2}.\)
On peut s’amuser longtemps comme ça à énoncer des formules. Le retard peut même devenir une « avance » puisque \(B^{-i}y_t = y_{t+i}\)mais certains préfèrent alors le dénommer \(F\) (comme Forward).
Lorsqu’on n’est pas habitué, la seule difficulté intellectuelle consiste à faire le lien entre un tel opérateur et les opérations algébriques qui lui sont appliquées ; si l’on écrit \(1 - B,\) il est bien évident que \(B\) n’est pas un nombre…
Soit dit en passant, une moyenne mobile (MM) peut être définie comme « une combinaison linéaire finie de puissances positives et négatives de l’opérateur retard » (« Séries temporelles et modèles dynamiques », C. Gourieroux et A. Monfort, Economica 1995, p. 56). Mais ce n’est pas là où nous voulons en venir. Vous comprenez qu’en attribuant des puissances à cet opérateur, on obtient des fonctions polynomiales auxquelles on peut faire subir additions, multiplications et j’en passe…
À titre d’exemple, prenons une MM pondérée non centrée utilisable pour prévoir le cours d’une action, actualisée chaque jour par récurrence. Le dernier cours observé compte pour 3, le précédent pour 2 et celui d’avant pour 1. La prévision en \(t + 1\) peut être synthétisée de cette façon :
\(y_{t+1}\) \(=\) \(\left(\frac{1}{2} + \frac{1}{3}B + \frac{1}{6}B^2 \right)y_t\)
Cette fonction polynomiale fait partie de l’espace vectoriel des fonctions du même degré, donc multipliable par un scalaire (le nombre d’actions possédées) et pouvant être ajoutée à d’autres fonctions (les autres actions détenues, la somme étant la prévision en \(t + 1\) du montant global du portefeuille par MMP).
L’opérateur de différenciation
Cet opérateur a pour symbole un nabla, c'est-à-dire un triangle pointé vers le bas. La définition est on ne peut plus simple.
\(\nabla y_t\) \(=\) \(y_t - y_{t-1}\) \(=\) \(y_t - By_t\) \(=\) \(y_t(1 - B)\)
Là encore, il peut être répété plusieurs fois en étant appliqué à lui même. Exemple de la différence seconde :
\(\nabla (\nabla)y_t\) \(=\) \(\nabla^2 y_t\) \(=\) \(y_t(1 - 2B + B^2)\)
Il existe aussi tous les cas où cet opérateur ne s’applique pas à \(t - 1\) mais à un recul supérieur. Ainsi, il permet d’éliminer une saisonnalité additive. Dans ce cas, le nombre de fois où on l’applique s’appelle l’ordre de désaisonnalisation. Si l’ordre est de 2 sur une désaisonnalisation mensuelle, notre nabla se trouvé ainsi paré : \(\nabla^2_{12}\)

ARIMA
C’est essentiellement dans le champ des processus stochastiques que ces deux opérateurs sont utilisés. Le nabla permet d’ôter une tendance linéaire, la différence seconde élimine une tendance quadratique et les autres ordres de différenciation s’occupent de diverses bizarreries (en fait ils sont très peu utilisés).
Voir une utilisation en page de processus MA.
Exercice
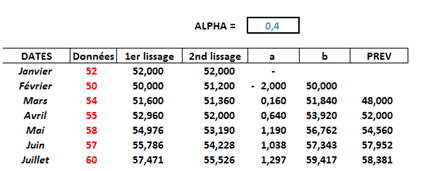
Le tableau suivant est extrait de la page sur le lissage exponentiel double (LED). Vérifier sur juillet l’égalité du LED qui fait intervenir nos deux chers opérateurs, à savoir :
\(\nabla^2y_t\) \(=\) \([1 - 2(1 - \alpha)B\) \(+\) \((1 - \alpha)^2B^2]e_t\)
Corrigé
À quoi est égal le terme de gauche de l'équation ? On note les évolutions des observations d’un mois sur l’autre (en rouge) : -2, +4, +1, +3, -1 et +3. Les différences secondes sont tout simplement les évolutions de ces différences, c'est-à-dire +6, -3, +2, -4 et +4. Pour juillet, la différence seconde est donc égale à 4.
Pour détailler le terme de droite, on a besoin des trois derniers \(e_t,\) c’est-à-dire des erreurs de prévision (différences entre la première et la dernière colonne). Attention, les erreurs positives et négatives ne se compensent pas ! On prend les valeurs absolues ! Elles s’établissent à 1,619 pour juillet, à 0,952 pour juin (c’est-à-dire lorsqu’on applique \(B\)) et à 3,44 pour mai (\(B^2\)). On sait que \(\alpha\) a été choisi à 0,4. Le terme de droite de l’équation s’établit donc à \([1,619\) \(+\) \((2 × 0,6 × 0,952)\) \(+\) \((0,6^2 × 3,44)]\) \(=\) \(4.\)
La vie est belle, non ?
Pour les expressions des divers lissages exponentiels avec ces opérateurs, voir « Méthodes de prévision à court terme » de Guy Mélard, Ellipses 2007.
