Métrique du khi-deux
La notion de distance est au cœur des statistiques et de l’analyse de données. Au regard de tel(s) ou tel(s) critère(s), on estimera si nous sommes plus proches de notre animal de compagnie ou de l’homme des cavernes. Encore faut-il définir une métrique commune entre des critères hétérogènes qui ne se mesurent pas au ruban-mètre…
Plusieurs distances
Pour évaluer la proximité de variables quantitatives, on peut toujours représenter celles-ci sur un graphe et mesurer les distances entre des points comme on le ferait en géométrie, c’est-à-dire en utilisant la distance euclidienne :
\(\displaystyle{d(X,Y) = \sqrt{\sum_{i=1}^n (y_i - x_i)^2}}\)
Les statisticiens utilisent PRESQUE la distance euclidienne. Sous la forme ci-dessus, elle n’est pas très pratique. Si par exemple on établit un modèle de régression linéaire simple ou multiple, on minimise des distances entre des observations (représentées par un nuage de points) et une droite de régression qui les résume au mieux. La mesure est alors le carré de ces distances (prenez la formule de la distance euclidienne ci-dessus et ôtez la racine) et c’est pourquoi on parle de droite des « moindres carrés ».
En analyse de données, lorsque les points sont très nombreux et où plusieurs observations se situent fréquemment en un même point, nécessitant ainsi une pondération \(p,\) on utilise la notion très proche d’inertie.
\(\displaystyle{I = \sum_{i=1}^n p_id_i^2}\)

Distance du \(\chi ^2\)
Mesurons à présent quelque chose de très différent. Il ne s’agit plus de distances entre des points et une droite ou un barycentre mais entre des valeurs observées et des valeurs théoriques.
Cette différence entre observé et théorique est élevée au carré puis rapportée à cette même valeur théorique.
Supposons qu’on compare des effectifs observés \(O\) aux effectifs \(T\) que l’on observerait si la population épousait parfaitement une fonction de densité donnée, par exemple le poids des habitants d’un village par tranches de 5 kg. La distance retenue, dite du \(\chi^2,\) sera la suivante (\(i\) représentant chaque tranche de poids).
\(\displaystyle{d^2 = \sum_{i=1}^n \frac{(O_i - T_i)^2}{T_i}}\)
C’est la problématique du test du \(\chi^2\) d’adéquation. En effet, la distance qu’on a définie suit, sous certaines conditions, une loi du \(\chi^2\) à \(n - 1\) degrés de liberté.
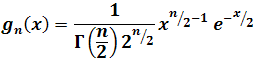{kind=link}
Supposons à présent que l’on cherche si deux caractères qualitatifs d’une population sont liés. Cette fois-ci, nos données sont encore des effectifs mais présentés sous forme de tableau à double entrée et non plus en simple colonne.
Nous réalisons alors un test du \(\chi^2\) d’indépendance, mesurant pour cela les distances entre chaque effectif observé (c’est-à-dire chaque case du tableau) et une répartition parfaitement aléatoire. La distance se définit donc de la même façon, sauf qu’on la présente évidemment avec deux indices (lignes et colonnes) :
\(D^2\) \(=\) \(\displaystyle{\sum_{i,j} \frac{(O_{ij} - T_{ij})^2}{T_{ij}}}\) \(=\) \(\displaystyle{\sum_{i,j} \frac{O_{ij}^2}{T_{ij}} -N}\)
Exemple tiré de l’épreuve 10 du DECS 1984 :
- Sur 80 entreprises classées défaillantes, 48 décident une modernisation de la gestion. Au bout de la période d’observation on constate que 25 d’entre elles ont faillite et que, sur les 32 entreprises qui n’ont pas modifié leur gestion, 25 ont fait faillite. Tester à l’aide du \(\chi^2\) (Khi-deux), au risque de \(1\,\%,\) puis de \(5\,\%,\) l’indépendance entre le changement de gestion et la faillite.
Il s’agit d’un test d’indépendance. Les éléments de correction ne traiteront que la distance du \(\chi^2.\)
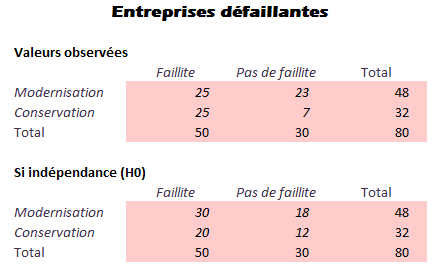
Calculons la distance à l’aide des deux formules équivalentes :
\(\displaystyle{\frac{(-5)^2}{30}}\) \(+\) \(\displaystyle{\frac{5^2}{18}}\) \(+\) \(\displaystyle{\frac{(-5)^2}{20}}\) \(+\) \(\displaystyle{\frac{5^2}{12}}\)
\(\approx\) \(0,83333 + 1,3889 + 1,25 + 2,0833\) \(\approx\) \(5,556.\)
Ou bien :
\(\displaystyle{\frac{25^2}{30}}\) \(+\) \(\displaystyle{\frac{23^2}{18}}\) \(+\) \(\displaystyle{\frac{25^2}{20}}\) \(+\) \(\displaystyle{\frac{7^2}{12}} - 80\)
\(\approx\) \(20,8333\) \(+\) \(29,3889\) \(+\) \(31,25\) \(+\) \(4,0833\) \(-\) \(80\) \(\approx\) \(5,556.\)
La table du \(\chi^2\) à 1 degré de liberté nous indique que l’on ne rejette pas l’hypothèse d’indépendance au seuil de \(1\,\%\) (6,63) mais qu’on la rejette au seuil de \(5\,\%\) (3,84, soit \(< 5,556\)).
Distance du phi²
Nous allons encore customiser notre distance pour l’adapter à un autre terrain.
Faisons une analyse factorielle sur variables qualitatives : analyse factorielle des correspondances (AFC) ou analyse des correspondances multiples (ACM). La problématique est assez proche et la métrique reste la même, à ceci près que la valeur du \(\chi^2\) est divisée par l’effectif. On note parfois cette distance \(\phi^2,\) du nom de l’indicateur de mesure d’association ainsi défini.
