Test de la médiane et correction de Yates
Ici, pas de méthode révolutionnaire. Non, ce test non paramétrique qui vous offre la possibilité de comparer \(k\) échantillons indépendants avec mesure ordinale est mis en œuvre et compréhensible avec une facilité déconcertante. Il s’agit ni plus ni moins d’un test d’indépendance du khi² à \(k - 1\) degrés de liberté (c’est-à-dire 1 ddl dans le cas le plus courant d’une comparaison de deux échantillons).
Posons le cadre
On le présente parfois comme l’équivalent d’un test des signes appliqué aux échantillons indépendants (c’est-à-dire non appariés). Bien que de construction assez différente, le test de Mann-Whitney est souvent concurrent de celui de la médiane.
Une condition préalable : la taille des deux échantillons confondus (qui ne sont pas nécessairement de même taille) doit être supérieure à une vingtaine d’unités. Sinon, on se tourne vers le test exact de Fisher.
On teste l’hypothèse selon laquelle les populations ont la même médiane. Drôle d'idée ? Supposons qu’un établissement de crédit dispose de deux grilles de score différentes pour les véhicules d’occasion et l’électroménager. Ces deux grilles présentent des distributions différentes : une note de 500 peut constituer un mauvais score sur une grille et un bon score sur l’autre, par exemple. Comment comparer les deux clientèles alors qu’un test d’égalités de moyennes n’a aucun sens ? En se rabattant sur les médianes !
Comment procéder ?
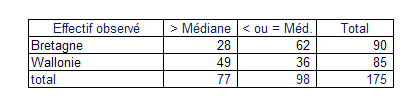
D’abord, la présentation des chiffres peut être réalisée par un collégien : on cherche la médiane générale et on reporte dans un tableau de contingence l’effectif qui se trouve au-dessous et au-dessus pour chacun des échantillons.
La suite des opérations est plus technique mais peut s’effectuer grâce à un tableur.
On observe si la probabilité d’obtenir la même proportion dans chaque échantillon est la même (soit \(50\,\%\) au-dessous de la médiane et \(50\,\%\) au-dessus). Cette probabilité est donnée par la loi hypergéométrique. Et c’est ce bon vieux test d’indépendance du \(\chi ^2\) qui prend le relais.
Examinons sans plus attendre un exemple…
Exemple
Une fromagerie fait réaliser une enquête auprès de sa clientèle dans deux régions d’Europe : Bretagne et Wallonie. Les répondants donnent leur avis sur un nouveau fromage à partir d’échelles d’Osgood à sept niveaux. Le responsable du marketing a estimé, à tort ou à raison, que deux échelles synthétisent convenablement l’opinion du consommateur. La première porte sur le goût et la seconde est un mix des autres caractéristiques (odeur, apparence, packaging…), ce qui revient à attribuer une note globale entre 2 et 14. Avant de lancer le fromage sur le marché, notre responsable aimerait vérifier la cohérence entre les notes attribuées par chaque échantillon et les ventes réalisées par des distributeurs pilotes. On ne prend jamais assez de précautions… Il octroie généreusement dix minutes au chargé d’études pour lui apporter une réconfortante réponse.
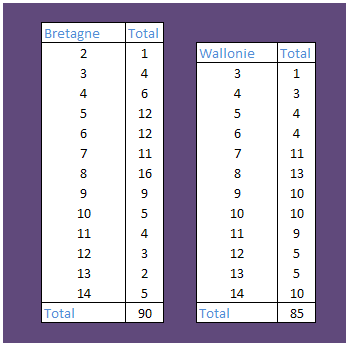
Les données sont présentées ici dans des tableaux synthétiques mais notre chargé d’étude dispose des résultats en liste avec le tableur, aussi le calcul des médianes est-il immédiat : 7 pour la Bretagne, 9 pour la Wallonie et 8 en global.
Un test d’indépendance du \(\chi ^2\) à 1 ddl se présente alors ainsi :
Reste à réaliser le test proprement dit. Pour un exemple avec tableur et quelques logiciels de statistiques, vous pouvez vous rendre en page de test d’indépendance du khi², sorties de logiciels. Ici, nous procédons à un test en ligne à l’adresse suivante (lien désuet) : http://socr.ucla.edu/htmls/SOCR_Analyses.html.
Sélection de chi-square test contingency table.
Résultat :

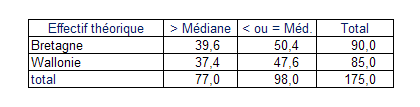
Cet état synthétise les deux tableaux réalisés avec tableur. On voit que la statistique du \(\chi ^2\) s’établit à 12,493. La p-value étant quasi nulle, on peut conclure sans prendre de gros risques que la différence est significative… Notre responsable du marketing sera conforté dans son opinion si cet écart corrobore une différence des ventes. Sinon, il peut s’interroger soit sur le sérieux des enquêteurs, soit sur un critère sociologique de discordance entre opinion et acte d’achat, soit sur sa propre trouvaille d’additionner deux échelles.

La correction de Yates
Dans la mesure où la statistique du \(\chi ^2\) est surestimée dans la situation d'un seul degré de liberté, on apporte généralement une correction : dans chaque case du tableau où l’effectif théorique est supérieur à l’observé, on ajoute 0,5. Dans le cas inverse, on retranche 0,5. Ceci conduirait, dans notre exemple, à modifier le tableau de contingence pour retenir les valeurs 28,5, 61,5, 48,5 et 36,5. La p-value calculée à partir de ces chiffres s’établit à 0,000719. Cette modification n’ébranle en rien nos conclusions.
