SCR, MSE, RMSE, MAE et MAPE
Le propre des techniques prédictives et prévisionnelles est d’envisager d’une façon ou d’une autre ce qui devrait être, selon l’idée qu’on se fait d’une réalité. Pour cela on collecte des données puis on les traite. Ce traitement se traduit par une modélisation sous forme d'équation(s) et par une validation. Hélas, il y aura toujours des écarts entre nos résultats et cette facétieuse réalité. Les raisons sont multiples et n'allons pas les énumérer. Le cas le plus pervers est celui d’un modèle qui prévoit exactement une valeur mais où une erreur de mesure laisse croire qu’il est mauvais.
Des modèles plus ou moins bons
Le terme modèle est ici pris au sens très large. Il peut résulter d'une régression ou de n'importe quelle technique prévisionnelle. Les prévisionnistes sont d'ailleurs de grands consommateurs d’indicateurs qui permettent, soit avec recul, soit en temps réel, de valider ou non leurs choix de techniques et de paramètres (coefficients de régression, constante d'un lissage exponentiel…). Des experts de tous domaines se fondent sur leur intime conviction ou sur des critères déjà éprouvés pour envisager des séries de pannes, de cours de bourse (analyse technique ou fondamentale), de survenances de maladies… Toute prévision ou prédiction chiffrée, qu’elle sorte d’un cerveau, d'une IA ou d'un modèle statistique, doit être confrontée a posteriori à la réalité.
Enfin, une technique peut être comparée à une autre sans faire référence aux chiffres réels mais pour estimer dans quelle mesure le résultat sera plus précis (échantillonnage stratifié plutôt qu’aléatoire simple, par exemple).
Des erreurs peuvent être commises en amont de l'analyse mais on ne s'intéressera ici qu'aux écarts entre le modèle et les observations grâce auxquelles il a été établi. Peut-être par esprit de vengeance, les statisticiens les traitent de « résidus » (du moins dans le cadre des régressions).
Comment mesurer ces écarts ?
Dans le domaine des statistiques, il existe toujours cette fâcheuse multiplicité des mesures : dispersions, distances, tendances, écarts… Tous ces indicateurs peuvent être mesurés avec des tas d’instruments (notez bien que le terme « fâcheux » ne doit faire plaisir qu'aux amateurs de sciences exactes qui cherchent vainement une sécurité mathématique pour modéliser des comportements humains et économiques, car c’est tout le sel des métiers de la data de savoir quel outil doit être utilisé dans telle circonstance !)

Le plus simple : on considère les écarts algébriques [réels – prévus] comme la distribution d'une variable, pour laquelle on calcule divers indicateurs de dispersion descriptifs (écart-type, par exemple). Mais ce ne sont pas les meilleurs outils de mesure : à titre d’illustration, s’il existe un biais se traduisant par une erreur de prévision systématiquement égale à \(+1\) sans autre erreur, l'écart-type des écarts est égal à zéro… En revanche, l’observation d'une telle série d’écarts permet de détecter un biais contrairement aux indicateurs ci-dessous, calculés sur des carrés ou des valeurs absolues. Il ne faut donc pas négliger cet outil, qui peut s'appuyer sur des graphiques.
Voici cinq indicateurs propres aux mesures d’écarts sur variables quantitatives. D’autres techniques mesurent les liens entre variables qualitatives, notamment le test d'indépendance du khi². Les coûts associés aux erreurs ne sont pas abordés ici.
Ci-dessous, on notera \(y_i\) une valeur prise par une variable expliquée et \({\widehat y_i}\) la valeur telle qu'elle aurait été prévue par le modèle. \(n\) est l'effectif.
La somme des carrés des résidus (SCR, on trouve parfois la notation SCres. En anglais : Sum of Squared Errors). Comme on mesure des carrés, on majore l’importance des grosses erreurs.
\(\displaystyle{{SCR} = {\sum\limits_{i = 1}^n {\left( {{y_i} - {{\widehat y}_i}} \right)} ^2}}\)
Bien entendu, quand un indicateur est une somme, il n'a d'intérêt qu'à titre de comparaison entre deux séries de même effectif et de même mesure. Mais sa principale utilisation n'est pas d'être un indicateur final. C'est surtout une notion liée à la régression (voir la page droite des moindres carrés).
Le carré moyen des erreurs (MSE pour Mean Square Error ou MCE pour moyenne des carrés des erreurs) : c’est la moyenne arithmétique des carrés des écarts entre prévisions du modèle et valeurs observées.
C’est la valeur à minimiser dans le champ d’une régression simple ou multiple (voir les moindres carrés). La méthode est fondée sur la nullité de la moyenne des résidus. Mais la moyenne de leurs carrés n'est généralement pas nulle. Cette moyenne n'est autre que la variance résiduelle que l'on cherche à minimiser (Cf. le théorème de König).
La formule de calcul change selon le contexte puisque la somme des carrés est divisée par un nombre de degrés de liberté. Si l’on divise la SCR par \(n\) dans le cas d’une série chronologique, on la divise par \(n-2\) lorsque l’on observe les résidus d’une régression simple et par \(n - k - 1\) dans le cas d’une régression multiple (\(k\) étant le nombre de variables explicatives).
Si l'on compare deux estimateurs sans biais, le meilleur est bien sûr celui qui présente la MCE la plus faible.
L’erreur quadratique moyenne (RMSE) : racine carrée du précédent.
L’erreur absolue moyenne (EAM ou MAE pour Mean Absolute Error) : moyenne arithmétique des valeurs absolues des écarts.
Ces quatre indicateurs servent surtout à comparer plusieurs modèles ou prévisions par rapport à une série de valeurs observées, ou encore plusieurs méthodes entre elles. L’indicateur suivant permet en outre la comparaison entre séries d’écarts.
L’erreur absolue moyenne en pourcentage (Mean Absolute Percentage Error, alias MAPE) : moyenne des écarts en valeur absolue par rapport aux valeurs observées. C’est donc un pourcentage et par conséquent un indicateur pratique de comparaison. Hélas, petit inconvénient, le MAPE ne peut s’appliquer qu’à des valeurs strictement positives. Il permet donc de juger si le système de prévision des ventes est bon, mais il est inefficace pour apprécier la qualité d’estimations de résultats qui peuvent être soit des bénéfices soit des pertes (ça tombe bien, il est un peu stupide de prévoir directement un solde plutôt que ces composantes positives ou négatives).
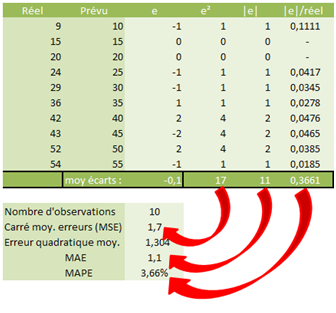
Exemple de détail de calcul (avec Excel) :
Pour aller plus loin
Il existe d’autres indicateurs pour évaluer des modèles de régression ou prévisionnels entre eux, comme l’AIC d’Akaïke ou le BIC de Schwartz. Dans le cadre prévisionnel, voir notamment « Méthodes de Prévision à court terme » de G. Mélard (éd. Ellipses. 2007) pp 31- 32.
Exemple de comparaison de deux méthodes en vue de choisir des constantes de lissage, sur SPSS : voir lissage de Holt. Le critère utilisé est la somme des carrés des erreurs.
